Log file analysis is usually a topic that would make anyone but the most techy of SEOs run for the hills. But if you can wade through the jungle of jargon, there is a true gold mine of data that awaits you.
The aim of this guide is to make log file analysis as understandable as possible. While primarily aimed at users performing a log file analysis for the first time, more experienced SEOs may still benefit from some of the tips.
This guide to log file analysis will explain the following:
- What log file data is and why it is useful
- How to perform a log file audit / what tools to use
- How to interpret log file data
- How to apply this to your website for SEO and other practical purposes
Ready to get started? Let’s dive in.
What Is a Log File?
Log files are records kept by your server of who accesses your website and what assets are accessed. This could be a person or a bot such as Googlebot. These files contain information such as the client that is accessing the information, a timestamp, user-agent and other details regarding the request. Most hosting solutions automatically keep log files for a certain period of time. Usually, these are made available only to the webmaster or owner of that particular domain.
A log file entry usually looks something like this:
66.249.66.1 – – [30/Sep/2017:16:09:05 -0400] “GET /dashboards/ HTTP/1.1” 200 “-” “Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)”
We return to this a little later. First, let’s start with some of the basics.
Why Should I Care?
The main reason for learning about and understanding log files lies in the information that they contain: While analytics tools like Google Analytics can provide you with a wealth of invaluable information, they do not tell the whole story. There is information stored in log files that is simply not available via any other means. This data has many valuable applications for SEO and other purposes such as site maintenance or protecting against stolen content.
URLs, Servers, HTTP Protocols: The Building Blocks of Log Files
To really understand log files its first important to run through a few basic definitions. Feel free to skip these if you are already familiar with URLs, HTTP requests etc.
URLs
A URL (Uniform Resource Locator) is commonly referred to as a web address. It mainly consists of three key ingredients:
- The protocol (also called scheme) – this is the method that is used to carry out the request to the server. HTTP is one of the most common methods for doing this, as is its secure counterpart HTTPS.
- Domain name – this is the name of your site. Typically, when a user/client wants to access your site, a DNS (Domain Name Server) converts the requested Domain name (e.g. keyword-hero.com) into an IP address that points to the server where your webpage is physically hosted. So the Domain Name Server is more or less a big directory of Domain names and their corresponding IP addresses
- File name (also called path) – this is the resource on the server that is accessed. This is the part of the URL appended by a single slash “/” followed by the filename. This usually refers to a web page such as “/dashboards” but can also be a resource such as an image or video.
Taken together a URL looks like this:
Protocol://domain-name/file
http://keyword-hero.com/dashboards
Query Strings and Fragments
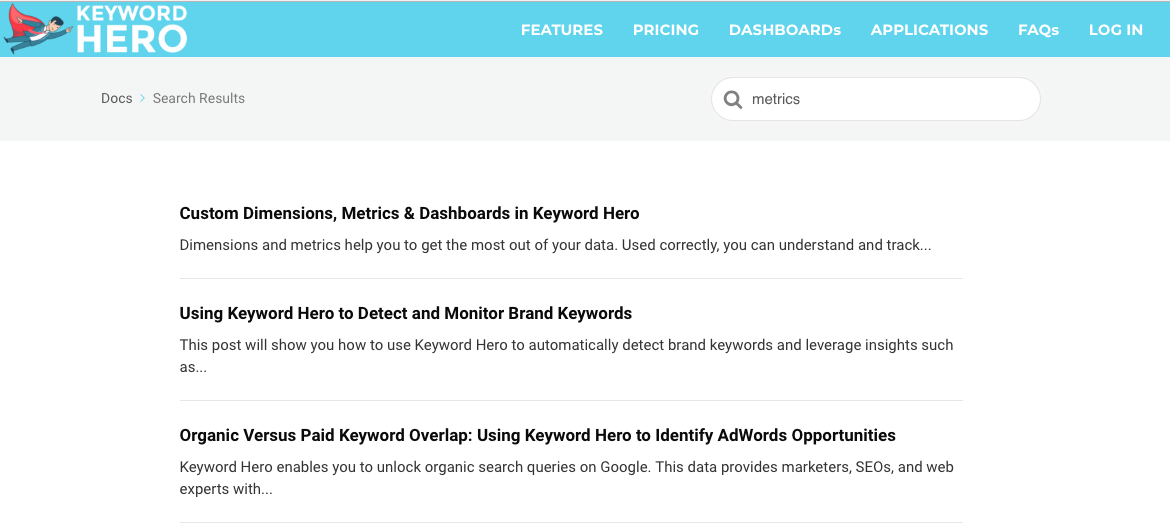
Additionally, a query string can be appended to a URL by using a “?”. The “?” query string character is often used when a search is performed within a webpage as in the example below, where we search for articles containing the keyword “metrics”. Usually, a variable is set to a specific value, with a letter specifying the variable followed by a “=” to specify the value. Multiple variables can be set and concatenated with the ampersand “&”
The corresponding URL for searching the docs page for keyword “metrics” is:
https://keyword-hero.com/docs/?s=metrics&ht-kb-search=1
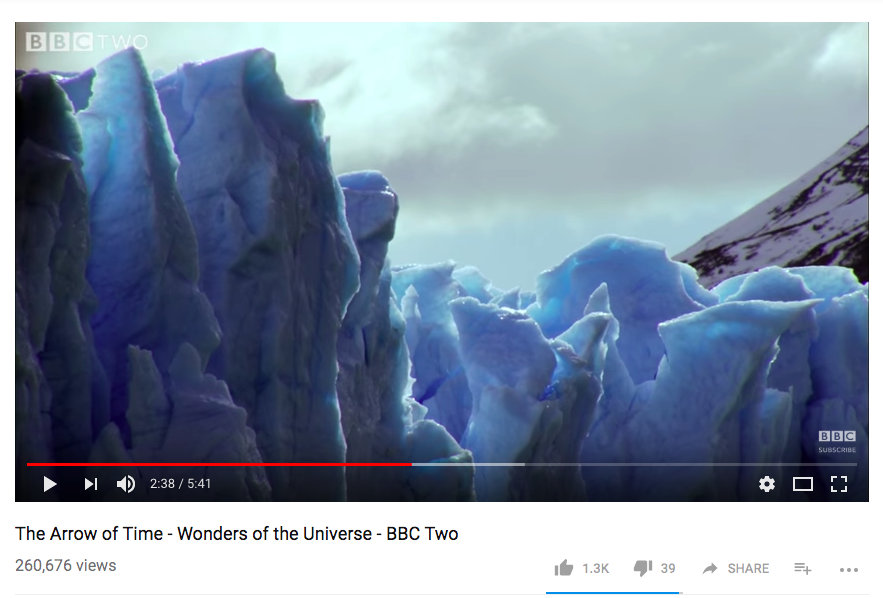
Another example is when you share a link to a Youtube or Vimeo video at a particular point in time. In this example, the URL queries the video asset and plays it from that point in time.
https://youtu.be/vLACGFhDOp0?t=2m38s
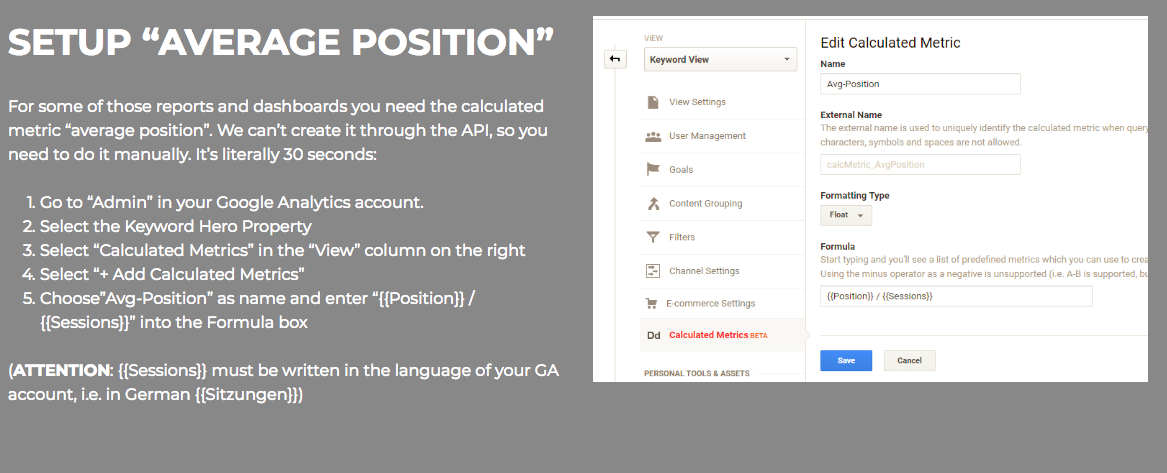
The other element we can append to URLs is a fragment. You may know this already as an anchor, denoted by the “#”. On the Keyword Hero dashboards page, there are many different dashboards that are each denoted by a “#” anchor in the underlying HTML. If we want to jump to the section about “Average Position”, we append the corresponding anchor, or fragment, to the URL.
https://keyword-hero.com/dashboards#keywordperformance
Knowing the fundamentals of how URLs are made up goes a long way to understanding log files. Why? Well, most of this information is recorded by the server when a request is made. This information, along with some other elements, forms the fundamentals of log files.
The final piece of the log file puzzle lies in HTTP requests.
HTTP
HTTP (Hypertext Transfer Protocol) enables communication between clients and servers. A client is something that generates requests to view web pages, such as a web browser. The server handles and processes these requests. HTTP allows different types of request to be made. One of the most common types of requests is called a GET request, which used for accessing web pages or assets.
When a client communicates with a server, status codes indicate the success (or failure) of the particular request. Here is a very brief list of some of the most common.
Each code is grouped by the first digit as follows:
- 2xx indicates success
- 3xx denotes redirects
- 4xx signifies client errors
- 5xx is reserved for server errors
HTTP Status Code – 200 OK
The request has succeeded.
HTTP Status Code – 301 Moved Permanently
The requested resource has been assigned a new permanent URL. This is the classic redirect.
HTTP Status Code – 307 Temporary Redirect
The requested resource resides temporarily under a different URL.
HTTP Status Code – 403 Forbidden
The server understood the request, but access was denied. Usually, the client does not have the correct permissions.
HTTP Status Code – 404 Not Found
The server has not found anything matching the URL request, i.e. the client requested a resource not existing on the server. This is one of the most common error codes and can have several reasons:
- The user entered a wrong URL manually
- Your or external sites contain wrong links to pages on your site
- The URL it correct, but the resource somehow got lost
HTTP Status Code – 500 Internal Server Error
The server encountered an unexpected condition which prevented it from fulfilling the request.
HTTP Status Code – 503 Service Unavailable
Your web server is unable to handle your HTTP request at the time. This can be due to server overload, crash or malicious attack.
User Agent
The user-agent string is sent with an HTTP request and gives us information about the client browser, operating system or piece of software operating on behalf of the client. Often, the user-agent is what allows us to identify what bot is crawling our site.
Note that there are different Googlebots for desktop, mobile, ads, images, videos etc. Here are the user agents for the desktop and mobile Googlebot respectively:
Googlebot desktop:
Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)
Googlebot mobile:
Mozilla/5.0 (iPhone; CPU iPhone OS 9_1 like Mac OS X) AppleWebKit/601.1.46 (KHTML, like Gecko) Version/9.0 Mobile/13B143 Safari/601.1 (compatible; AdsBot-Google-Mobile; +http://www.google.com/mobile/adsbot.html)
Putting it all Together
Ok great. But what does all of this have to do with log files? Well, actually quite a lot. All of the individual information we have just looked up is exactly what a log file is made up of. Log files are simply records of every request that happens between a client and a server. Every time you browse a webpage, you are creating a log file entry somewhere.
What Data Does a Log File Contain?
Well, in a way we have already answered this question. A log file contains the address of the client trying to access your hosting server. It also includes the asset it is trying to access and in the case of a GET request a message which might be appended to the URL.
Let’s take another look at the log file entry from the beginning:
66.249.66.1 – – [30/Sep/2017:16:09:05 -0400] “GET /dashboards/ HTTP/1.1” 200 “-” “Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)”
We can break this log file down into the following elements:
- Client IP
- Timestamp (date & time)
- Method (GET / POST)
- Request URL
- HTTP status code
- User-agent
The client IP is the IP of the that is accessing data from our server. Later on, we will see how to perform a reverse DNS lookup with this IP address to see who or what domain or bot is accessing our site.
The timestamp is fairly obvious – this is the time at which the request was made to the server. Some log files may include the timezone offset in UTC. Here we see a -0400 which refers to UTC -4, or in this particular case, Eastern US time.
Next up is the method. For the most part, we are only concerned with GET requests.
Following this, we have the URL path. This corresponds the to the file that is being accessed. In our example, this is the /dashboards landing page.
Next, we have the HTTP status code. As mentioned above, this refers to the success or the failure of the request. In our example, we see the code is 200, which signifies the request was a success.
Finally, the user agent tells us extra information about the client. Here we can see the client was a Mozilla browser and that the Googlebot actually made the request to access our website, and that it was the desktop Googlebot based on the user agent.
Additional Information
Other information can be sent with each HTTP request as well. Often what is actually sent depends on privacy settings and network restrictions relating to a hosting solution or country of origin. Other information could also include the following:
- Hostname
- Local Server IP
- Bytes downloaded
- Time taken
How Can I Access Log Files?
Depending on your server client or hosting solution, log files are usually stored automatically and made available for a certain period of time. They are only available to webmasters in most cases.
These files can usually be downloaded or exported. They are typically in the .log file format. How you access these files entirely depends on your web hosting solutions. Please check with your web host about the correct way to do this. Solutions like Log Hero can import this data directly into Google Analytics.
How Can I Perform Log File Analysis?
One of the classic ways to perform log file analysis is to simply use Excel to comb through often up to hundreds of thousands of rows of raw data. This is incredibly time-consuming and tedious for SEOs.
Log Hero makes the whole process much easier. We have developed simple plugins that allow you to import your log file data from your web hosting solution straight into Google Analytics via the Google Analytics Management API.
First, let’s look at some – by no means exhaustive – examples or practical applications of log file analysis:
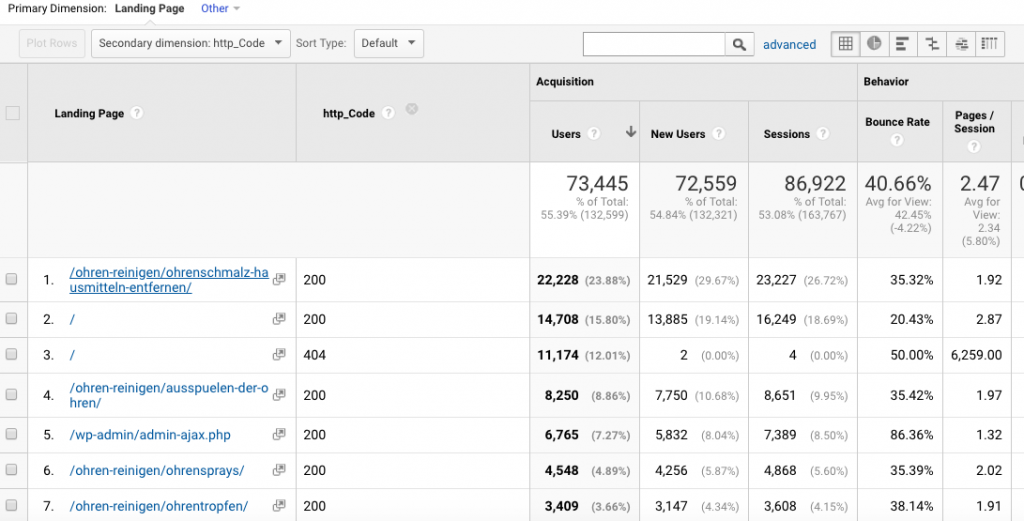
Identify and Eliminate HTTP Errors such as 404s, 500s
Particularly with large websites, it’s perfectly normal to see the occasion 404 HTTP code when content is no longer available. But what about your high traffic pages. Are they all performing exactly as they should? Using log files in conjunction with traffic data, it’s straightforward to reduce 404 errors on important high traffic pages.
In Log Hero, status codes are available as a custom dimension. This greatly speeds up the process and provides greater insight by combining log file data with analytics data.
Search Engine Crawls
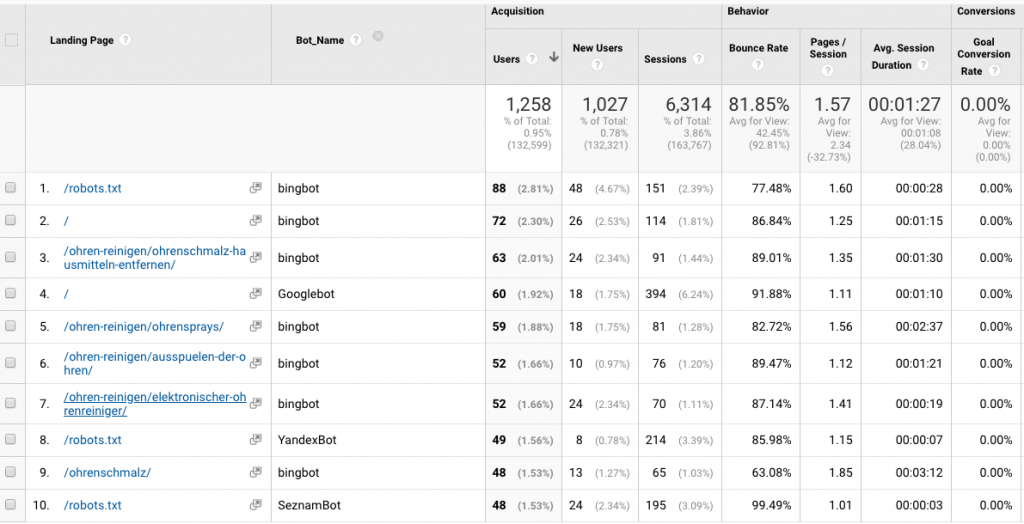
While Google Webmaster Tools can provide certain information on crawl errors and how Google crawls your site, there is so much more information available. Also by looking at log files, it is relatively straightforward to see all bots that are crawling your site. This has a clear advantage that you don’t necessarily have to have a webmaster account – if this is even available – with every single search provider.
Not only this, but this also includes RSS bots that check if you have new content to add to their RSS feeds. The data provided in log files can help you make sure your time-critical content such as new blog posts is getting interpreted correctly by RSS bots. Not only that but exactly which RSS bots are crawling your content.
In Log Hero you can see which bots are crawling your site as a custom dimension. Log Hero also automatically filters spam to ensure your data is accurate and save you the time of doing this manually.
Reverse DNS lookups
Remember our previous log file example? Let’ take another look. Although the user agent states “Googlebot” how do we actually know that this is actually Google crawling our site?
66.249.66.1 – – [30/Sep/2017:16:09:05 -0400] “GET /dashboards/ HTTP/1.1” 200 “-” “Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)”
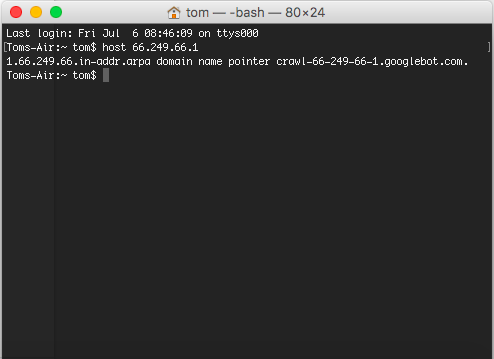
One way to verify this is to perform what is called a reverse DNS lookup. This means, we use the DNS, i.e. the directory of Domain names and IP addresses, the other way round and look up the Domain name corresponding to an IP address.
Open up the command line and use the command “host” followed by the client IP address you want to perform the look upon.
> host 66.249.66.1
1.66.249.66.in-addr.arpa domain name pointer crawl-66-249-66-1.googlebot.com.
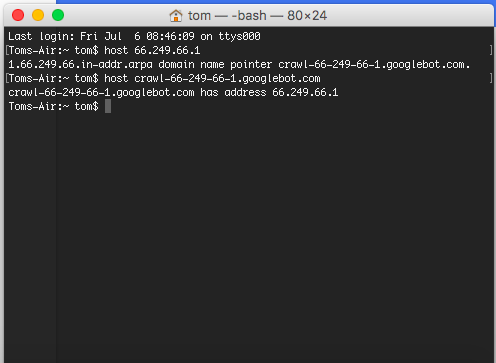
The response does indeed output “googlebot.com” as the domain. To further verify this you can perform a forward DNS lookup by taking the output and performing the same command. We would use the command “host” then follow this with the output “crawl-66-249-66-1.googlebot.com”.
If the response to this corresponds exactly to the IP you have entered you have successfully verified that it is indeed Googlebot performing the crawl.
Log Hero actually automatically determines whether your site is being crawled by a genuine search engine bot.
In summary, when it comes to search engine crawls, log files can help resolve the following
- Helping you improve accessibility errors such as 404 and 500 errors
- Check whether spam bots are crawling your page / verifying that actual search engines are crawling the page
Log Hero: The Easiest Way to Analyze Log Files
Log Hero makes Google’s and Bing’s (and all other) bots visible in Google Analytics, so you can monitor how they crawl your website. As if the bots were people and in real-time. It’s log analysis taken to the next level.
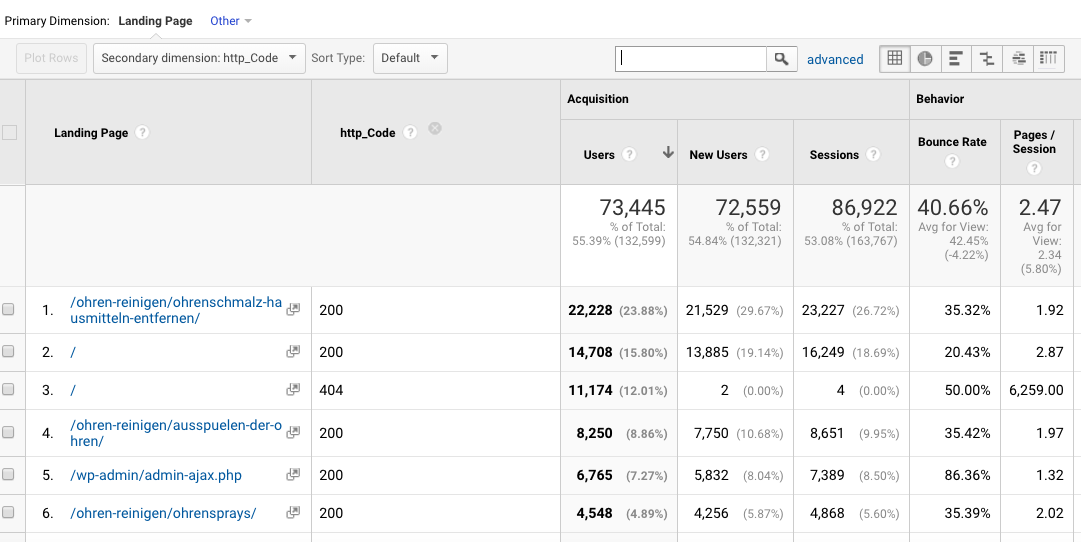
Log Hero can make analyzing log file much easier by doing a lot of the manual work for you. Not only this but by combining it and visualizing it directly alongside your Google Analytics data, you can treat the data from your log files as custom dimensions.
For example, imagine you wanted to filter by HTTP 404 errors on a page by page basis. Log Hero makes this possible. You can also filter by user agent, such as Googlebot, to see which search engines are crawling which pages. This data combined with your Google Analytics traffic data offers endless SEO potential.
Log Hero allows the following custom dimensions to be taken from your log files:
- Bot Name – Bot Name is the real name of the bot that is crawling your website. We maintain one of the most extensive and most complete lists of bots, which we identified through their IPs and transmitted User Agents.
- Is Bot – Is Bot is a binary true / false answer to whether the session was triggered by a bot. If true, it was a bot, if false, it was a human.
- Bot IP – This is the bot’s IP address. The IP address will only be transmitted if we are sure that a bot really triggered the session, so you won’t ever get any issues with privacy laws such as GDPR.
- Method – This explains what request method the bot used to fetch the content of your site. Here is an explanation of all possible methods by Mozilla.
- Status Code – The HTTP Status Code refers to how your site responds upon being called, either by bots or humans. The most well-known is the infamous 404 if a URL was called but couldn’t be found.
- Page Load Time – This is how many milliseconds it took for the server to make the entire content of the site available to whoever requested it, whether it was a bot or a human.
- User Agent – Anyone requesting information from a server identifies himself via a user agent, even if he/she is just surfing with a browser (to see your UA, ask Google here).
Summary: Get Started with Log Files Today and Unlock a Gold Mine of Data
We have seen that log files contain information that simply cannot be found anywhere else. This is not only extremely useful for keeping tabs on site performance, but also for SEO purposes.
One huge advantage of using log file data is that it gives you information on every entity that requests a web page or asset. This means that not only can you see who is accessing your website, but how your website is being crawled by search engines
By analyzing how Google and other search engines crawl your site, you can optimize our pages to be as crawl friendly as possible. Additionally, we have seen that Log Hero can make performing these type of log file audits much easier and quicker.
Get started with Log Hero today and unlock a gold mine of log file data.